"The other direction, as exemplified by prefix tuning (Li & Liang, 2021), faces a different challenge. We observe that prefix tuning is difficult to optimize and that its performance changes non-monotonically in trainable parameters, confirming similar observations in the original paper. More fundamentally, reserving a part of the sequence length for adaptation necessarily reduces the sequence length available to process a downstream task, which we suspect makes tuning the prompt less performant compared to other methods."
This is key imo: "More fundamentally, reserving a part of the sequence length for adaptation necessarily reduces the sequence length available to process a downstream task".
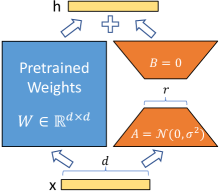
LoRA conversely has different downsides. LoRA can be used in two ways: merged or unmerged. Unmerged (which is how it's trained) incurs a non-trivial computation cost. Merged means you are modifying the model weights, which means you are stuck with that one model on that device (though, this usually applies for most implementations for the unmerged versions too).
The benefit of prompt and prefix tuning (note: these are two separate methods) is that you can serve different soft-prompts and soft-prefixes efficiently with a single shared set of model weights.
The hit seems to be in energy/cpu not time since the W0 computation is in parallel with the BAx. (My assumption based on the latency claims in paper.) So an issue in edge deployments (battery life, etc.).
> you are stuck with that one model on that device
Upfront I have 0 clue on the actual numbers, but from a purely software architecture pov [in unmerged setup], having that W0 forward process once with n distinct BAx paths (for distinct fine tunings!) would address that, no?
[p.s. say an application that takes as input A/V+Txt, runs that through an Ensemble LoRA (ELoRA™ /g) which each participant contributing its own BAx finetuing processing, sharing the single pre-trained W0.]
> My assumption based on the latency claims in paper.
The latency claims are based on the merged version, where the modifications are merged into the model weights. Hence there is no latency cost, since the final model has the same shape as the original.
> having that W0 forward process once with n distinct BAx paths (for distinct fine tunings!) would address that, no?
The tl;dr is that that works, but is more expensive. Not ridiculously more expensive, but certainly more expensive that processing a few additional tokens with prefix/prompt tuning.
> Merged means you are modifying the model weights, which means you are stuck with that one model on that device (though, this usually applies for most implementations for the unmerged versions too).
If one is careful with floating point issues, it's straightforward to unmerge the weights.
Right, it's mathematically easy (again, up to floating point issues) to recover the weights as needed, but in terms of distribution/serving I'm guessing the plan is to have the original weights and carry around the LoRA weights and merge as necessary.
(Also, I'm assuming you're the first author of LoRA.)
Yes, the plan is to keep the original weights in VRAM and merge/unmerge LoRA weights on the fly. You can even cache a large library of LoRA ckpts in RAM.
{kind=link}
Not exactly the same, to be sure. But fulfills a similar need: more efficient "fine tuning" of a large model.